Hệ thống phát hiện xâm nhập (Intrusion Detection Systems - IDS) là hệ thống theo dõi, phát hiện và cảnh báo sự xâm nhập, cũng như các hành vi khai thác trái phép tài nguyên, xâm hại đến tính bí mật, toàn vẹn và sẵn sàng của hệ thống. Có nhiều phương pháp xây dựng phát hiện xâm nhập, nhưng xu hướng mới đang được nhiều nhà khoa học quan tâm là dựa trên mô hình học máy. Nhiều bộ dữ liệu đã được cung cấp để triển khai pha huấn luyện của các mô hình học máy. Nghiên cứu này tập trung xây dựng bộ dữ liệu phù hợp để áp dụng phương pháp cây quyết định, trích ra từ bộ dữ liệu khác.
Có nhiều nghiên cứu về việc ứng dụng học máy trong phát hiện xâm nhập mạng, phát hiện tấn công ứng dụng website. Một số nghiên cứu nổi bật liên quan gần đây có thể đề cập đến như:
Công trình [1], Rashid cùng cộng sự đã thực nghiệm nghiên cứu một số thuật toán học máy và học sâu trên 2 bộ dữ liệu NSL-KDD và CIDDS-001, kết quả thu được chỉ số đo về độ chính xác lên đến 99%. Tuy nghiên, nghiên cứu chỉ tập trung vào phát hiện tấn công DDoS trên hệ thống chung, chưa cụ thể các loại hình tấn công khác nhau.
Công trình [2], Thakkar và Lohiya đã nghiên cứu tổng quan về 13 bộ dữ liệu được sử dụng trong xây dựng các hệ thống phát hiện xâm nhập, kết quả cho thấy cần cập nhật dữ liệu mới để tăng hiệu suất của các hệ thống này. Việc xây dựng bộ dữ liệu phải gắn liền với kịch bản mạng thực tế trong môi trường thật. Nghiên cứu đã đánh giá 2 bộ dữ liệu CIC-IDS-2017 và CSE-CICIDS-2018 phù hợp nhất trong việc xây dựng các hệ thống phát hiện xâm nhập.
Với công trình [3], nhóm tác giả Sharafaldin đã trình bày về nghiên cứu xây dựng tập dữ liệu CSIIDS-2017. Trong khi nghiên cứu [4], D’hooge cùng cộng sự tiến hành thực nghiệm trên bộ dữ liệu CICIDS2017 và CSE-CIC-IDS2018, nghiên cứu đã đánh giá 2 bộ dữ liệu trong áp dụng học máy để phát hiện xâm nhập mạng, kết quả cho thấy bộ phân loại sử dụng thuật toán Rừng ngẫu nhiên đạt hiệu quả tốt nhất.
Công trình nghiên cứu số [5] là đề xuất của J. Kim cùng cộng sự xây dựng một hệ thống phát hiện xâm nhập dựa trên học sâu với nền tảng sử dụng bộ dữ liệu CIC-IDS-2018, tiến hành thử nghiệm phân loại trên các ngày cụ thể và đạt kết quả phân loại tốt nhất là 99%. Tuy nhiên, đối với một hệ thống thật thì việc phân loại này chưa hợp lý vì đối với mỗi ngày sẽ có một phân loại khác nhau.
Trong nghiên cứu số [6], nhóm nghiên cứu của C.Yin đã trình bày sự thiếu sót của học máy truyền thống trong bài toán phân loại dữ liệu từ dữ liệu lớn. Các nhà nghiên cứu đã thực hiện ứng dụng mạng RNN để xử lý dữ liệu lớn đã được số hóa và tiền xử lý dữ liệu. Thí nghiệm được xây dựng trên bộ dữ liệu NSL-KDD, bộ dữ liệu sau khi được xử lý, số lượng thuộc tính đã thay đổi từ 41 thuộc tính thành 122 thuộc tính. Kết quả, mô hình đạt được độ chính xác lên đến 83,28%.
Có nhiều bộ dữ liệu dùng cho việc huấn luyện tấn công mạng, bao gồm cả tấn công website như: Bộ dữ liệu DARPA của Viện Công nghệ Massachusetts; Bộ dữ liệu KDD Cup 1999, được hình thành trong cuộc thi “Các công cụ khai phá dữ liệu và nghiên cứu tri thức quốc tế lần thứ 3”; Bộ dữ liệu NSL-KDD được Tavallaee cùng các cộng sự công bố năm 2009; Bộ dữ liệu UNSW-NB15 được công bố năm 2015 bởi phòng thí nghiệm Cyber Range của Trung tâm An ninh mạng Australia (ACCS) công bố; và gần đây là bộ dữ liệu CSE-CIC-IDS2018.
Với CSE-CIC-IDS2018, đây là bộ dữ liệu nâng cấp dựa trên mô hình của bộ dữ liệu CIC-IDS2017. Bộ dữ liệu này thu thập đầy đủ lưu lượng mạng trong vòng 10 ngày. Số lượng máy tấn công được sử dụng là 50 máy, số máy nạn nhân bao gồm 420 máy trạm và 50 máy chủ. Tương tự như CIC-IDS 2017, bộ dữ liệu này được xây dựng dựa trên CICFlowMeter với 80 đặc trưng lưu lượng mạng được trích xuất. Có thể thấy bộ dữ liệu CSE-CIC-IDS2018 có đầy đủ các đặc trưng của bộ dữ liệu CIC-IDS 2017 nhưng toàn diện và đa dạng hơn.
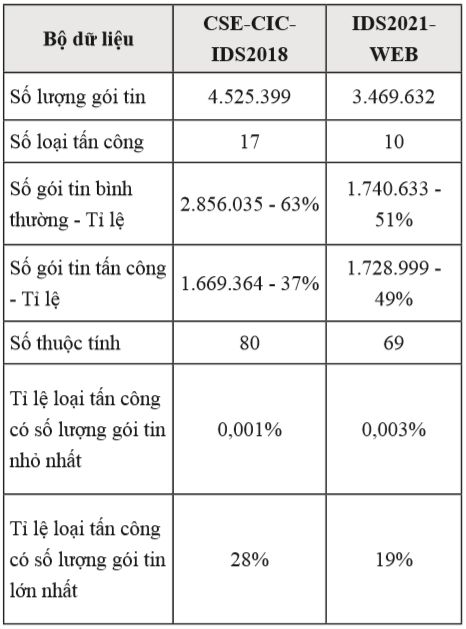
Bộ dữ liệu CSE-CIC-IDS2018 bao gồm 10 tập dữ liệu CSV có gán nhãn các ngày thu thập, bao gồm 4.525.399 gói tin, mỗi gói tin có 80 thuộc tính. Mô phỏng với 17 loại tấn công, số gói tin có số lượng nhiều nhất là gói tin gán nhãn bình thường (2.856.035 gói tin, chiếm 63%), trong khi đó gói tin có số lượng ít nhất là gói tin gán nhãn SQL Injection (53 gói tin, chiếm 0,001%).
Về tấn công ứng dụng website, bộ dữ liệu thực nghiệm được xây dựng dựa trên cơ sở bộ dữ liệu CSECIC-IDS2018 bằng cách lọc các gói tin được gửi đến cổng 80 và cổng 443 như trong Hình 1 (sau đây gọi là IDS2021-WEB).
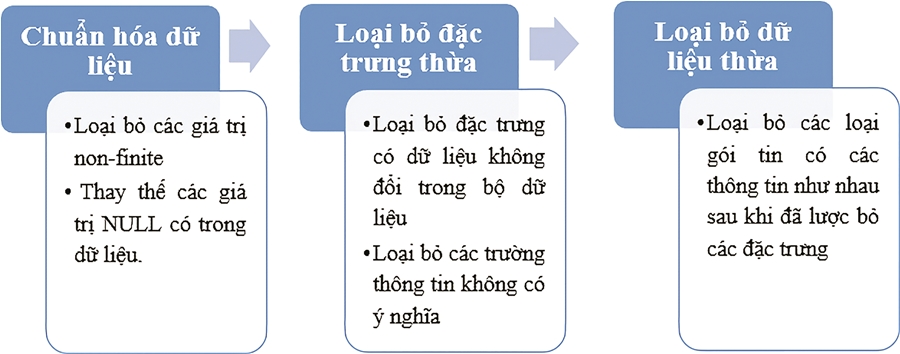
Hình 1. Các bước tiền xử lý dữ liệu bộ dữ liệu IDS2021-WEB
Bộ dữ liệu IDS2021-WEB được thực hiện tiền xử lý dữ liệu theo các công đoạn được mô tả tại Hình 1 cụ thể như sau:
Sau khi loại bỏ các giá trị non-finite và thay thế các giá trị NULL, kiểm tra và loại bỏ các cột dữ liệu dư thừa trong bộ dữ liệu. Kết quả thực hiện kiểm tra nhận thấy các trường: BwdPSHFlags, FwdURGFlags, BwdURGFlags, CWEFlagCount, FwdByts/bAvg, FwdPkts/bAvg, FwdBlkRateAvg, BwdByts/bAvg, BwdPkts/bAvg, BwdBlkRateAvg có số liệu không đổi, loại khỏi bộ dữ liệu.
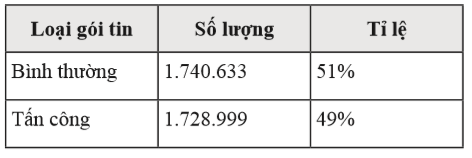
Tiếp tục loại các trường như Timestamp, Protocol vì không có ý nghĩa. Cuối cùng thu được bộ dữ liệu IDS2021-WEB với 69 thuộc tính. Sau khi tiền xử lý dữ liệu, kết quả thu được bộ dữ liệu với tổng số lượng 3.469.632 gói tin (Bảng 1), trong đó bao gồm 10 loại tấn công khác nhau nhằm vào ứng dụng website.
Bảng 1. Bảng thống kê số lượng các loại gói tin trong IDS2021-WEB
So sánh bộ dữ liệu IDS2021-WEB và CSE-CICIDS2018 được mô tả tại Bảng 2, điều này thể hiện rằng bộ dữ liệu mới IDS2021-WEB có kích thước nhỏ hơn, tỉ lệ giữa gói tin tấn công và bình thường cân bằng, số lượng thuộc tính giảm. Tuy nhiên tỉ lệ mất cân bằng về số lượng gói tin giữa các loại tấn công vẫn có sự chênh lệch khá lớn, nhưng đã cải thiện so với bộ dữ liệu CSECIC-IDS2018.
Bảng 2. So sánh bộ dữ liệu IDS2021-WEB và CSE-CIC-IDS2018
Áp dụng kỹ thuật trực quan hóa dữ liệu dựa trên t-NSE [13] được thể hiện trong Hình 2, có thể thấy phân phối của các gói tin tấn công tương đối rõ, tuy nhiên một số loại tấn công được phân phối khá gần với các gói tin được dán nhãn bình thường.
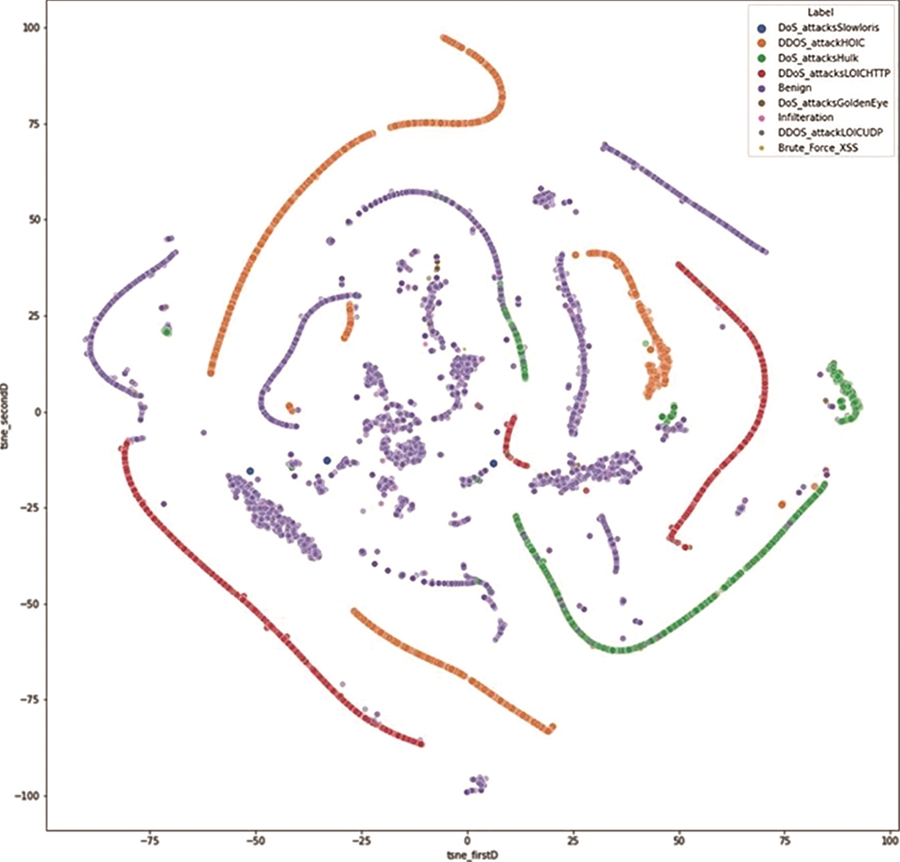
Hình 2. Trực quan hóa dữ liệu sử dụng trên thuật toán t-NSE
Hình 3 mô tả về quá trình thực nghiệm của nghiên cứu bao gồm các bước: Phân tích bộ dữ liệu CSECIC-IDS2018; Trích chọn xây dựng bộ dữ liệu mới IDS2021-WEB và thực nghiệm bộ dữ liệu mới xây dựng với các thuật toán học máy.
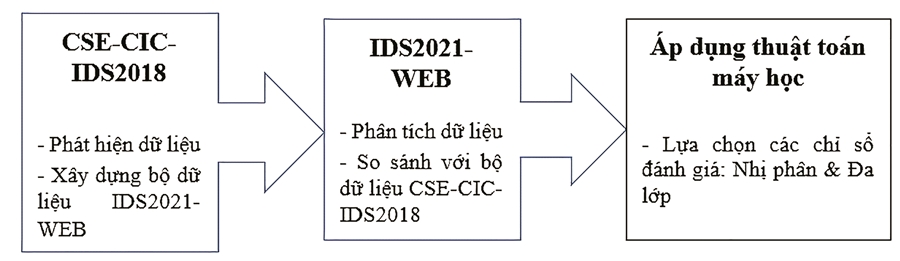
Hình 3. Mô hình tiến hành thực nghiệm
Thực nghiệm đánh giá trên ngôn ngữ lập trình Python, môi trường Google Collaboratory, sử dụng GPU. Kỹ thuật học máy được sử dụng trên các mô hình: Navie Bayes, Gradient Boosting, k-NN, Cây quyết định, Cây mở rộng, Rừng ngẫu nhiên. Trước khi tiến hành thực nghiệm, công việc tiền xử lý dữ liệu được thực hiện để mô hình đánh giá đạt kết quả cao nhất.
Để đánh giá các thuật toán học máy, thực hiện 2 phương pháp thực nghiệm là phân loại 2 lớp và phân loại đa lớp. Trong đó, phân loại 2 lớp là trường hợp kiểm tra gói tin có phải là gói tin tấn công hay không, với phân loại đa lớp là kiểm tra xem gói tin đó có phải gói tin tấn công và thuộc loại tấn công nào. Do đó, xây dựng bộ dữ liệu có gán nhãn phù hợp với phương pháp thực nghiệm.
Tiếp tục chia bộ dữ liệu thành 2 tập con, bao gồm tập “train” và tập “test”. Kích thước và đặc điểm các bộ dữ liệu như sau:
Bảng 3. Kích thước bộ dữ liệu huấn luyện và kiểm tra

Sau khi chia thành công các bộ dữ liệu huấn luyện, tiến hành thực nghiệm và sử dụng các phương pháp đánh giá kết quả. Các bước thử nghiệm và đánh giá kết quả sẽ được nhóm tác giả trình bày tại phần II của bài báo.
|
TÀI LIỆU THAM KHẢO 1. A. Rashid, M. J. Siddique, và S. M. Ahmed, “Machine and Deep Learning Based Comparative Analysis Using Hybrid Approaches for Intrusion Detection System”, trong 2020 3rd International Conference on Advancements in Computational Sciences (ICACS), Lahore, Pakistan, tháng 2 2020, tr 1–9. doi: 10.1109/ICACS47775.2020.9055946. 2. A. Thakkar và R. Lohiya, “A Review of the Advancement in Intrusion Detection Datasets”, Procedia Computer Science, vol 167, tr 636–645, 2020, doi: 10.1016/j. procs.2020.03.330. 3. I. Sharafaldin, A. Habibi Lashkari, và A. A. Ghorbani, “Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization”, trong Proceedings of the 4th International Conference on Information Systems Security and Privacy, Funchal, Madeira, Portugal, 2018, tr 108–116. doi: 10.5220/0006639801080116. 4. L. D’hooge, T. Wauters, B. Volckaert, và F. De Turck, “Inter-dataset generalization strength of supervised machine learning methods for intrusion detection”, Journal of Information Security and Applications, vol 54, tr 102564, tháng 10 2020, doi: 10.1016/j.jisa.2020.102564. 5. J. Kim, Y. Shin, và E. Choi, “An Intrusion Detection Model based on a Convolutional Neural Network”, J Multimed Inf Syst, vol 6, số p.h 4, tr 165–172, tháng 12 2019, doi: 10.33851/JMIS.2019.6.4.165. 6. C. Yin, Y. Zhu, J. Fei, và X. He, “A Deep Learning Approach for Intrusion Detection Using Recurrent Neural Networks”, IEEE Access, vol 5, tr 21954–21961, 2017, doi: 10.1109/ ACCESS.2017.2762418. 7. “IDS 2018 | Datasets | Research | Canadian Institute for Cybersecurity | UNB”. |
TS. Nguyễn Văn Căn, Đoàn Ngọc Tú (Trường Đại học Kỹ thuật - Hậu cần Công an nhân dân)

10:00 | 21/10/2022

17:00 | 18/01/2023

17:00 | 09/09/2022

16:00 | 09/08/2022

13:00 | 17/04/2024
Mới đây, Cơ quan An ninh mạng và Cơ sở hạ tầng Hoa Kỳ (CISA) đã phát hành phiên bản mới của hệ thống Malware Next-Gen có khả năng tự động phân tích các tệp độc hại tiềm ẩn, địa chỉ URL đáng ngờ và truy tìm mối đe dọa an ninh mạng. Phiên bản mới này cho phép người dùng gửi các mẫu phần mềm độc hại để CISA phân tích.

13:00 | 30/05/2023
Mặc dù mạng 5G sẽ mang lại nhiều lợi ích cho xã hội và người dân, nhưng 5G cũng làm tăng thêm những rủi ro mới. Bảo mật 5G là vấn đề chung mà thế giới đang phải đối mặt, do đó cần tăng cường nghiên cứu, học hỏi kinh nghiệm của các nước để làm phong phú hơn kịch bản ứng phó của quốc gia mình.

12:00 | 16/03/2023
Metaverse (vũ trụ ảo) là một mạng lưới rộng lớn gồm các thế giới ảo 3D đang được phát triển mà mọi người có thể tương tác bằng cách sử dụng thực tế ảo (VR), hay thực tế tăng cường (AR). Công nghệ này hứa hẹn mang lại sự trải nghiệm mới mẻ, thú vị cho người dùng cũng như mang đến những cơ hội kinh doanh cho các doanh nghiệp trong việc chuyển đổi cách thức hoạt động. Tuy nhiên, bên cạnh những lợi ích thì Metaverse cũng đặt ra những thách thức và nguy cơ về vấn đề bảo mật trong không gian kỹ thuật số này.

10:00 | 30/01/2023
Blockchain (chuỗi khối) là một cơ sở dữ liệu phân tán với các đặc trưng như tính phi tập trung, tính minh bạch, tính bảo mật dữ liệu, không thể làm giả. Vì vậy công nghệ Blockchain đã và đang được ứng dụng vào rất nhiều lĩnh vực trong đời sống như Y tế, Nông nghiệp, Giáo dục, Tài chính ngân hàng,... Bài báo này sẽ giới thiệu về công nghệ Blockchain và đề xuất một mô hình sử dụng nền tảng Hyperledger Fabric để lưu trữ dữ liệu sinh viên như điểm số, đề tài, văn bằng, chứng chỉ trong suốt quá trình học. Việc sử dụng công nghệ Blockchain để quản lý dữ liệu sinh viên nhằm đảm bảo công khai minh bạch cho sinh viên, giảng viên, các khoa, phòng chức năng. Đồng thời giúp xác thực, tra cứu các thông tin về văn bằng, chứng chỉ góp phần hạn chế việc sử dụng văn bằng, chứng chỉ giả hiện nay.
08:00 | 11/01/2024 | Chính sách - Chiến lược

09:00 | 10/01/2024 | Giải pháp khác

09:00 | 05/01/2024|Chính sách - Chiến lược
09:00 | 05/01/2024|An ninh – Quốc Phòng

Lược đồ chữ ký số dựa trên hàm băm là một trong những lược đồ chữ ký số kháng lượng tử đã được Viện Tiêu chuẩn và Công nghệ Quốc gia Mỹ (NIST) chuẩn hóa trong tiêu chuẩn đề cử FIPS 205 (Stateless Hash Based Digital Signature Standard) vào tháng 8/2023. Bài báo này sẽ trình bày tổng quan về sự phát triển của của lược đồ chữ ký số dựa trên hàm băm thông qua việc phân tích đặc trưng của các phiên bản điển hình của dòng lược đồ chữ ký số này.
09:00 | 01/04/2024

Những ngày gần đây, liên tục các kênh YouTube với lượng người theo dõi lớn như Mixigaming với 7,32 triệu người theo dõi của streamer nổi tiếng Phùng Thanh Độ (Độ Mixi) hay Quang Linh Vlogs - Cuộc sống ở Châu Phi với 3,83 triệu người theo dõi của YouTuber Quang Linh đã bị tin tặc tấn công và chiếm quyền kiểm soát.
10:00 | 22/04/2024


















