.jpg)
Cách ChatGPT lấy dữ liệu đào tạo
Theo một nghiên cứu của OpenAI đã công bố, ChatGPT3 đã được đào tạo trên một số bộ dữ liệu như: Common Crawl, WebText2, Book1 và Book2 hay Wikipedia. Lượng dữ liệu đào tạo lớn nhất đến từ Common Crawl, cung cấp quyền truy cập vào thông tin web thông qua kho lưu trữ thu thập dữ liệu web mở. Bot Common Crawl, còn được gọi là CCBot, tận dụng Apache Nutch để cho phép các nhà phát triển xây dựng các trình thu thập thông tin quy mô lớn.
Phiên bản mới nhất của CCBot thu thập dữ liệu từ Amazon AWS và tự nhận dạng nó bằng User agent “CCBot/2.0”. Các doanh nghiệp nếu muốn cho phép sử dụng CCBot không nên chỉ dựa vào User agent để nhận dạng nó, bởi vì nhiều bot xấu giả mạo User agent của họ để ngụy trang thành bot tốt và tránh bị chặn. Để cho phép sử dụng CCBot trên trang web của mình, người dùng cần sử dụng các thuộc tính như dải IP hoặc DNS Reverse. Để chặn ChatGPT, tối thiểu trang web của người dùng phải chặn lưu lượng truy cập từ CCBot.
Ba cách ngăn chặn CCBot
.png)
Scrapers luôn có thể tìm cách giải quyết
LLM sử dụng bot scraper để thu thập dữ liệu đào tạo. Mặc dù việc chặn CCBot có thể hiệu quả trong việc chặn những scraper ChatGPT ngày nay, nhưng không thể biết được tương lai của những scraper LLM sẽ ra sao. Nếu có quá nhiều trang web chặn OpenAI truy cập vào nội dung của họ, thì nhà phát triển có thể quyết định ngừng sử dụng robots.txt và có thể không khai danh tính trình thu thập thông tin của họ (crawler identity) trong User agent.
Một khả năng khác là OpenAI có thể sử dụng mối quan hệ hợp tác với Microsoft để truy cập scraper data của Microsoft Bing khiến tình hình trở nên khó khăn hơn đối với chủ sở hữu trang web. Các bot của Bing được xác định là Bingbot nhưng việc chặn chúng có thể gây ra sự cố khi ngăn trang web của người dùng được lập chỉ mục trên công cụ tìm kiếm Bing, dẫn đến có ít khách truy cập là con người hơn.
Người dùng có thể gặp phải các vấn đề tương tự bằng cách chặn LLM Bard của Google (đối thủ cạnh tranh với ChatGPT). Việc thu thập dữ liệu công khai được sử dụng để đào tạo Bard, nhưng có thể Bard đang hoặc sẽ được đào tạo bằng dữ liệu được thu thập bởi những người thu thập dữ liệu của Googlebot. Giống như Bingbot, việc chặn Googlebot có thể là không hợp lý, ảnh hưởng đến cách trang web của người dùng được lập chỉ mục và cách công cụ tìm kiếm Google hướng lưu lượng truy cập đến trang web của người dùng. Kết quả có thể dẫn đến lượng khách truy cập giảm nghiêm trọng.
Sử dụng plugin để truy cập dữ liệu trực tiếp
Một trong những hạn chế chính của các mô hình như ChatGPT là thiếu quyền truy cập vào dữ liệu trực tiếp. Vì được đào tạo trên tập dữ liệu (dataset) đã dừng vào năm 2021 nên nó không thể cung cấp thông tin cập nhật và phù hợp nhất. Đó là nơi các plugin xuất hiện.
Các plugin được sử dụng để kết nối LLM như ChatGPT với các công cụ khác và cho phép LLM truy cập dữ liệu bên ngoài có sẵn trực tuyến, có thể bao gồm dữ liệu riêng tư và tin tức thời gian thực. Plugin cũng cho phép người dùng hoàn thành các hành động trực tuyến (ví dụ: đặt chuyến bay hoặc đặt hàng) thông qua lệnh gọi API.
Một số doanh nghiệp đang phát triển plugin của riêng họ để cung cấp cách mới cho người dùng tương tác với nội dung/dịch vụ của họ thông qua ChatGPT. Tuy nhiên, tùy thuộc vào lĩnh vực, ngành nghề, việc cho phép người dùng tương tác với trang web thông qua plugin ChatGPT của bên thứ ba, điều này đồng nghĩa với việc người dùng nhìn thấy ít quảng cáo hơn, cũng như giảm lưu lượng truy cập vào trang web.
Cũng có thể thể nhận thấy rằng người dùng ít sẵn sàng trả phí cho các tính năng cao cấp hơn khi các tính năng có thể được sao chép thông qua plugin ChatGPT của bên thứ ba. Ví dụ: một ứng dụng web client không chính thức tương tác với trang web của doanh nghiệp có thể cung cấp các tính năng cao cấp thông qua giao diện người dùng.
Cách xác định các yêu cầu plugin ChatGPT
Tài liệu OpenAI nêu rõ rằng các yêu cầu có tiêu đề HTTP User agent cụ thể (với token: "ChatGPT-User") đến từ plugin ChatGPT. Tuy nhiên, tài liệu không nêu rõ rằng User agent được tiết lộ là User agent duy nhất có thể được các plugin sử dụng khi thực hiện các yêu cầu HTTP. Do đó, khi plugin ChatGPT tương tác với API của bên thứ ba, các API sau đó có thể thực hiện bất kỳ loại yêu cầu HTTP nào từ cơ sở hạ tầng của chính chúng. Hình dưới đây cho thấy điều gì sẽ xảy ra khi sử dụng "Live Sport Plugin" hư cấu với ChatGPT để nhận thông tin cập nhật về một sự kiện thể thao.
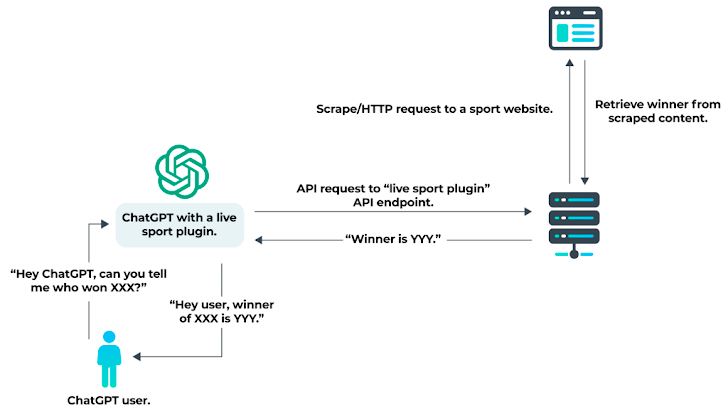
Minh họa sử dụng Live Sport Plugin với ChatGPT
Một plugin thực sự có thể đưa ra yêu cầu đối với API thể thao mà không cần phải tìm kiếm trang web thể thao. Trên thực tế, khi yêu cầu được thực hiện trực tiếp từ máy chủ lưu trữ API plugin, không có ràng buộc nào đối với user agent.
Cách chặn yêu cầu plugin ChatGPT
Trong quy trình tương tự như chặn web scraper của ChatGPT, người dùng có thể chặn yêu cầu từ các plugin khai báo sự hiện diện của chúng bằng chuỗi con "ChatGPT-User" theo User agent. Nhưng việc chặn User agent cũng có thể chặn người dùng ChatGPT khi chế độ "duyệt web (browsing)" được kích hoạt. Trái với những gì tài liệu OpenAI có thể chỉ ra, việc chặn yêu cầu từ "ChatGPT-User" không đảm bảo rằng ChatGPT và các plugin của nó không thể tiếp cận dữ liệu của bạn bằng các User agent token khác nhau.
Trên thực tế, plugin ChatGPT có thể thực hiện yêu cầu trực tiếp từ máy chủ lưu trữ API của họ bằng cách sử dụng bất kỳ User agent nào và thậm chí sử dụng trình duyệt tự động (headless browser - trình duyệt web không có giao diện đồ họa người dùng). Việc phát hiện các plugin không khai báo danh tính của chúng trong User agent yêu cầu các kỹ thuật phát hiện bot nâng cao.
Các bước tiếp theo người dùng nên làm
Việc có được bộ dữ liệu chất lượng cao về nội dung do con người tạo ra sẽ vẫn có tầm quan trọng đặc biệt đối với LLM. Về lâu dài, các công ty như OpenAI (được Microsoft tài trợ một phần) và Google có thể muốn sử dụng Bingbots và Googlebots để xây dựng bộ dữ liệu nhằm đào tạo LLM của họ. Điều đó sẽ gây khó khăn hơn cho các trang web trong việc từ chối thu thập dữ liệu, vì hầu hết các doanh nghiệp trực tuyến phụ thuộc rất nhiều vào Bing và Google để lập chỉ mục nội dung và hướng lưu lượng truy cập đến trang web của họ.
Các trang web có dữ liệu giá trị sẽ muốn tìm cách kiếm tiền từ việc sử dụng dữ liệu của họ hoặc từ chối đào tạo mô hình AI để tránh mất lưu lượng truy cập web và doanh thu quảng cáo cho ChatGPT và các plugin của nó. Nếu muốn từ chối, người dùng sẽ cần các kỹ thuật phát hiện bot nâng cao, chẳng hạn như lấy dấu vân tay, phát hiện proxy và phân tích hành vi để ngăn chặn bot trước khi chúng có thể truy cập dữ liệu của họ.
Các giải pháp nâng cao cho bot và chống gian lận sử dụng trí tuệ nhân tạo (AI) và học máy (ML) để phát hiện và ngăn chặn các bot lạ ngay từ yêu cầu đầu tiên, giữ cho nội dung an toàn trước các LLM scraper, plugin không xác định và các công nghệ AI đang phát triển nhanh chóng khác.
Hồng Đạt
(Theo The Hacker News)

10:00 | 28/08/2023

09:00 | 06/11/2023

15:00 | 06/10/2023

10:00 | 07/11/2023

18:00 | 22/09/2023

09:00 | 03/10/2023

09:00 | 25/10/2023

14:00 | 10/11/2023

09:00 | 05/06/2023

13:00 | 26/02/2024

11:00 | 26/04/2024

07:00 | 24/04/2023

14:00 | 11/10/2023

09:00 | 08/03/2024
Từ lâu, botnet là một trong những mối đe dọa lớn nhất đối với an ninh mạng, nó đã gây ra nhiều thiệt hại cho các tổ chức và doanh nghiệp trên toàn thế giới. Bài báo sẽ giới thiệu tới độc giả một số kỹ thuật phát hiện botnet bằng Honeynet và tính hiệu quả của chúng, đồng thời đề xuất một số hướng phát triển trong tương lai để nâng cao khả năng phát hiện và ngăn chặn botnet bằng Honeynet.

10:00 | 28/08/2023
Trước đây đã có những quan điểm cho rằng MacBook rất khó bị tấn công và các tin tặc thường không chú trọng nhắm mục tiêu đến các dòng máy tính chạy hệ điều hành macOS. Một trong những nguyên do chính xuất phát từ các sản phẩm của Apple luôn được đánh giá cao về chất lượng lẫn kiểu dáng thiết kế, đặc biệt là khả năng bảo mật, nhưng trên thực tế MacBook vẫn có thể trở thành mục tiêu khai thác của các tin tặc. Mặc dù không bị xâm phạm thường xuyên như máy tính Windows, tuy nhiên đã xuất hiện nhiều trường hợp tin tặc tấn công thành công vào MacBook, từ các chương trình giả mạo đến khai thác lỗ hổng bảo mật. Chính vì vậy, việc trang bị những kỹ năng an toàn cần thiết sẽ giúp người dùng chủ động nhận biết sớm các dấu hiệu khi Macbook bị tấn công, đồng thời có những phương án bảo vệ hiệu quả trước các mối đe dọa tiềm tàng có thể xảy ra.

16:00 | 21/03/2023
Theo đánh giá của các chuyên gia, phần lớn các vi phạm bảo mật dẫn đến các chiến dịch lừa đảo thành công đến từ lỗi của con người. Bài báo sau đây sẽ đưa ra một số phương thức để chúng ta có thể củng cố bức tường lửa con người thông qua mô hình thiết kế hành vi của Fogg (Tiến sĩ BJ Fogg - Đại học Stanford Mỹ).

13:00 | 06/12/2022
Cùng với sự gia tăng không ngừng của các mối đe dọa an ninh mạng, các tin tặc thay đổi, phát triển các chiến thuật và phương thức tấn công mới tinh vi hơn dường như xuất hiện liên tục. Trong khi đó, các chiến dịch tấn công nhắm vào cơ sở hạ tầng công nghệ thông tin của các tổ chức/doanh nghiệp (TC/DN) được các nhóm tin tặc thực hiện với tần suất nhiều hơn. Chính vì thế, việc xây dựng một chiến lược phòng thủ dựa trên bằng chứng được thực thi tốt là điều mà các TC/DN nên thực hiện để chủ động hơn trước các mối đe dọa trong bối cảnh các cuộc tấn công mạng đang trở nên khó lường và phức tạp.
08:00 | 11/01/2024 | Chính sách - Chiến lược

09:00 | 10/01/2024 | Giải pháp khác

09:00 | 05/01/2024|Chính sách - Chiến lược
09:00 | 05/01/2024|An ninh – Quốc Phòng

Lược đồ chữ ký số dựa trên hàm băm là một trong những lược đồ chữ ký số kháng lượng tử đã được Viện Tiêu chuẩn và Công nghệ Quốc gia Mỹ (NIST) chuẩn hóa trong tiêu chuẩn đề cử FIPS 205 (Stateless Hash Based Digital Signature Standard) vào tháng 8/2023. Bài báo này sẽ trình bày tổng quan về sự phát triển của của lược đồ chữ ký số dựa trên hàm băm thông qua việc phân tích đặc trưng của các phiên bản điển hình của dòng lược đồ chữ ký số này.
09:00 | 01/04/2024

Theo báo cáo năm 2022 về những mối đe doạ mạng của SonicWall, trong năm 2021, thế giới có tổng cộng 623,3 triệu cuộc tấn công ransomware, tương đương với trung bình có 19 cuộc tấn công mỗi giây. Điều này cho thấy một nhu cầu cấp thiết là các tổ chức cần tăng cường khả năng an ninh mạng của mình. Như việc gần đây, các cuộc tấn công mã độc tống tiền (ransomware) liên tục xảy ra. Do đó, các tổ chức, doanh nghiệp cần quan tâm hơn đến phương án khôi phục sau khi bị tấn công.
19:00 | 30/04/2024


















