
11:00 | 26/04/2024

10:00 | 26/04/2024

16:00 | 25/04/2024

14:00 | 25/04/2024

10:00 | 24/04/2024

10:00 | 24/04/2024
11:00 | 26/04/2024
11:00 | 26/04/2024
11:00 | 26/04/2024
10:00 | 26/04/2024
10:00 | 26/04/2024
16:00 | 25/04/2024
16:00 | 25/04/2024
14:00 | 25/04/2024
14:00 | 25/04/2024
14:00 | 25/04/2024
08:00 | 11/01/2024 | Chính sách - Chiến lược

09:00 | 10/01/2024 | Giải pháp khác

09:00 | 05/01/2024|Chính sách - Chiến lược
09:00 | 05/01/2024|An ninh – Quốc Phòng
11:00 | 26/04/2024

Apple đang đàm phán để sử dụng công cụ Gemini AI của Google trên iPhone, tạo tiền đề cho một thỏa thuận mang tính đột phá trong ngành công nghiệp AI.
11:00 | 26/04/2024
16:00 | 25/04/2024

14:00 | 25/04/2024
16:00 | 25/04/2024

Theo các chuyên gia, việc cấm tài sản ảo (VA) và nhà cung cấp tài sản ảo (VASP) sẽ khiến bỏ lỡ một thế hệ nhà đầu tư mới đang rất quan tâm tới Việt Nam nơi có 20% dân số sở hữu tài sản mã hoá. Do đó, cần thúc đẩy tiếp cận phổ biến chính sách quản lý VA-VASP theo Kế hoạch hành động Quốc gia về phòng và chống rửa tiền.

15:00 | 23/04/2024

09:00 | 19/04/2024

15:00 | 16/04/2024
11:00 | 26/04/2024

Các nhà nghiên cứu của công ty an ninh mạng BlackBerry đã phát hiện một chiến dịch gián điệp mạng nhắm vào người dùng iPhone ở khu vực Nam Á, với mục đích phân phối payload của phần mềm gián điệp có tên là LightSpy. BlackBerry cho biết chiến dịch này có khả năng cho thấy sự tập trung mới của các tác nhân đe dọa vào các mục tiêu chính trị và căng thẳng trong khu vực.

14:00 | 25/04/2024

14:00 | 24/04/2024
10:00 | 24/04/2024
09:00 | 19/04/2024
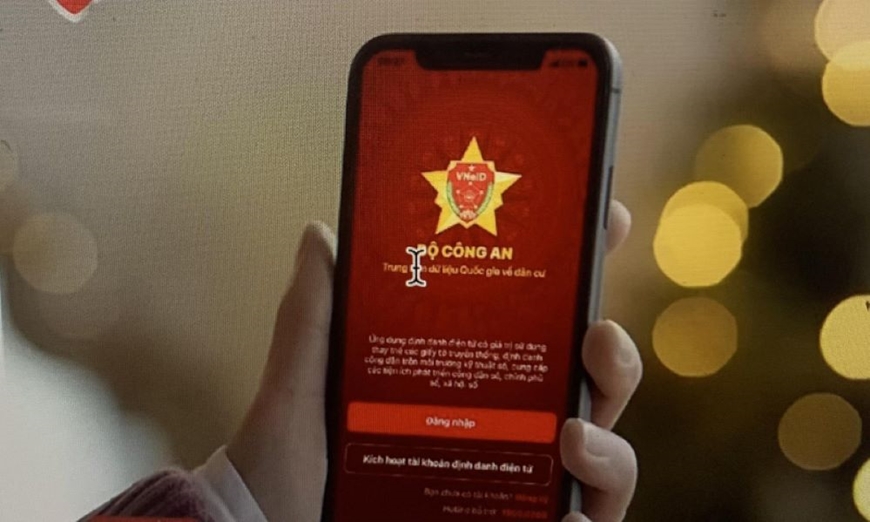
Thời gian gần đây, nhiều đối tượng xấu đã giả danh cơ quan công an gọi điện cho người dân yêu cầu ra công an phường để khắc phục sự cố đồng bộ VNeID mức 2. Đây là một hình thức lửa đảo mới nhằm chiếm đoạt toàn bộ tiền trong tài khoản ngân hàng của nạn nhân.

10:00 | 10/04/2024

09:00 | 01/04/2024

15:00 | 25/03/2024

10:00 | 22/04/2024

Những ngày gần đây, liên tục các kênh YouTube với lượng người theo dõi lớn như Mixigaming với 7,32 triệu người theo dõi của streamer nổi tiếng Phùng Thanh Độ (Độ Mixi) hay Quang Linh Vlogs - Cuộc sống ở Châu Phi với 3,83 triệu người theo dõi của YouTuber Quang Linh đã bị tin tặc tấn công và chiếm quyền kiểm soát.

13:00 | 17/04/2024

10:00 | 10/04/2024

07:00 | 08/04/2024
09:00 | 16/06/2023
09:00 | 09/12/2022
14:00 | 09/11/2022
10:00 | 28/09/2022
12:00 | 23/09/2022
11:00 | 24/03/2022
16:00 | 21/02/2022
16:00 | 30/12/2021
08:00 | 17/04/2024

Các nhà nghiên cứu tại tổ chức bảo mật phi lợi nhuận Shadowserver Foundation (California) cho biết hàng nghìn thiết bị Ivanti VPN kết nối với Internet có khả năng bị ảnh hưởng bởi một lỗ hổng thực thi mã từ xa.

08:00 | 04/04/2024

14:00 | 25/03/2024

09:00 | 08/03/2024
11:00 | 26/04/2024
Apple đang đàm phán để sử dụng công cụ Gemini AI của Google trên iPhone, tạo tiền đề cho một thỏa thuận mang tính đột phá trong ngành công nghiệp AI.

10:00 | 26/04/2024
10:00 | 26/04/2024
14:00 | 25/04/2024



































