
10:00 | 22/04/2024

08:00 | 17/04/2024

13:00 | 17/04/2024

13:00 | 17/04/2024

10:00 | 16/04/2024

17:00 | 12/04/2024
10:00 | 22/04/2024
10:00 | 22/04/2024
10:00 | 22/04/2024
10:00 | 22/04/2024
16:00 | 19/04/2024
15:00 | 19/04/2024
09:00 | 19/04/2024
09:00 | 19/04/2024
09:00 | 19/04/2024
09:00 | 19/04/2024
08:00 | 11/01/2024 | Chính sách - Chiến lược

09:00 | 10/01/2024 | Giải pháp khác

09:00 | 05/01/2024|Chính sách - Chiến lược
09:00 | 05/01/2024|An ninh – Quốc Phòng
10:00 | 22/04/2024

Những ngày gần đây, liên tục các kênh YouTube với lượng người theo dõi lớn như Mixigaming với 7,32 triệu người theo dõi của streamer nổi tiếng Phùng Thanh Độ (Độ Mixi) hay Quang Linh Vlogs - Cuộc sống ở Châu Phi với 3,83 triệu người theo dõi của YouTuber Quang Linh đã bị tin tặc tấn công và chiếm quyền kiểm soát.

10:00 | 22/04/2024

16:00 | 19/04/2024

15:00 | 19/04/2024
09:00 | 19/04/2024

Thực hiện nhiệm vụ được giao tại Chỉ thị 09/CT-TTg ngày 23/02/2024 của Chính phủ, Cục An toàn thông tin, Bộ Thông tin và Truyền thông (TT&TT) ban hành Sổ tay Hướng dẫn tuân thủ quy định pháp luật và tăng cường bảo đảm an toàn hệ thống thông tin (HTTT) theo cấp độ (Phiên bản 1.0).

15:00 | 16/04/2024

13:00 | 15/04/2024

12:00 | 12/04/2024
10:00 | 22/04/2024
Trong một xu hướng đáng lo ngại được Bitdefender Labs (Hoa Kỳ) phát hiện gần đây, tin tặc đang tận dụng sự quan tâm ngày càng tăng đối với AI để phát tán các phần mềm độc hại tinh vi. Những kẻ tấn công này đang tung ra các chiến dịch quảng cáo độc hại trên mạng xã hội, giả dạng các dịch vụ AI phổ biến như Midjourney, DALL-E và ChatGPT để đánh lừa người dùng.

09:00 | 19/04/2024

08:00 | 17/04/2024

15:00 | 16/04/2024
09:00 | 19/04/2024
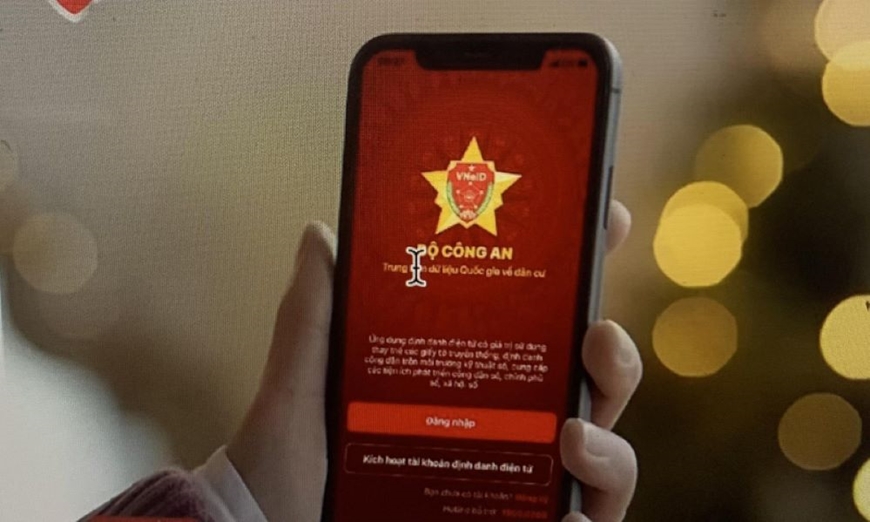
Thời gian gần đây, nhiều đối tượng xấu đã giả danh cơ quan công an gọi điện cho người dân yêu cầu ra công an phường để khắc phục sự cố đồng bộ VNeID mức 2. Đây là một hình thức lửa đảo mới nhằm chiếm đoạt toàn bộ tiền trong tài khoản ngân hàng của nạn nhân.

10:00 | 10/04/2024

09:00 | 01/04/2024

15:00 | 25/03/2024

10:00 | 22/04/2024
Những ngày gần đây, liên tục các kênh YouTube với lượng người theo dõi lớn như Mixigaming với 7,32 triệu người theo dõi của streamer nổi tiếng Phùng Thanh Độ (Độ Mixi) hay Quang Linh Vlogs - Cuộc sống ở Châu Phi với 3,83 triệu người theo dõi của YouTuber Quang Linh đã bị tin tặc tấn công và chiếm quyền kiểm soát.
13:00 | 17/04/2024

10:00 | 10/04/2024

07:00 | 08/04/2024
09:00 | 16/06/2023
09:00 | 09/12/2022
14:00 | 09/11/2022
10:00 | 28/09/2022
12:00 | 23/09/2022
11:00 | 24/03/2022
16:00 | 21/02/2022
16:00 | 30/12/2021
08:00 | 17/04/2024
Các nhà nghiên cứu tại tổ chức bảo mật phi lợi nhuận Shadowserver Foundation (California) cho biết hàng nghìn thiết bị Ivanti VPN kết nối với Internet có khả năng bị ảnh hưởng bởi một lỗ hổng thực thi mã từ xa.

08:00 | 04/04/2024

14:00 | 25/03/2024

09:00 | 08/03/2024
10:00 | 22/04/2024

Ngày 16/4, nhiều người dùng Facebook tại Việt Nam phản ánh về tình trạng không hiện thị các bài đăng trên trang cá nhân. Trong khi đó, nội dung vẫn được phân phối trên bảng tin bình thường.

09:00 | 19/04/2024

13:00 | 17/04/2024

13:00 | 16/04/2024




































